
Large-scale deep learning models take a long time to run and can benefit from distributing the work across multiple resources. TensorFlow can help you distribute training across multiple CPUs or GPUs. We’ll explain how TensorFlow distributed training works and show brief tutorials to get you oriented.
Introduction to TensorFlow Distributed Training
To run large deep learning models, or a large number of experiments, you will need to distribute them across multiple CPUs, GPUs or machines. TensorFlow can help you distribute your training by splitting models over many devices and carrying out the training in parallel on the devices.
Types of Parallelism in Distributed Deep Learning
There are two main methods of implementation that you can use to distribute deep learning model training: model parallelism or data parallelism. At times, a single approach will lead to better application performance, while at other times a combination of the two approaches will improve performance.
Model parallelism
In model parallelism, the model is segmented into different parts so you can run it in parallel. You can run each part on the same data in different nodes. This approach may decrease the need for communication between workers, as workers only need to synchronize the shared parameters.
Model parallelism also works well for GPUs in a single server that shares a high-speed bus and with larger models, as hardware constraints per node are not a limitation.
Data parallelism
In this mode, the training data is divided into multiple subsets. You run each subset on the same replicated model in a different node. You must synchronize the model parameters at the end of the batch computation to ensure they are training a consistent model because the prediction errors are computed independently on each machine.
Each device must, therefore, send notification of all changes, to all of the models of all the other devices.
Distributed TensorFlow using tf.distribute.Strategy
The DistributionStrategy API is an easy way to distribute training workloads across multiple machines. DistributionStrategy API is designed to give users access to existing models and code. Users only need to make minimal changes to the models and code to enable distributed training.
Supported types of distribution strategies
MirroredStrategy: Support synchronous distributed training on multiple GPUs on one machine. It creates one replica per GPU device. Each variable in the model is mirrored across all the replicas. Together, these variables form a single conceptual variable called MirroredVariable. TMirroredVariables are kept in sync with each other by applying identical updates.
mirrored_strategy = tf.distribute.MirroredStrategy()MultiWorkerMirroredStrategy: This is a version of MirroredStrategy for multi-worker training. It implements synchronous distributed training across multiple workers, each of which can have multiple GPUs. It creates copies of all variables in the model on each device across all workers.
communication_options = tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CommunicationImplementation.NCCL)
multi_worker_mirrored_strategy = tf.distribute.MultiWorkerMirroredStrategy(communication_options=communication_options)ParameterServerStrategy: Supports parameter servers. It can be used for multi-GPU synchronous local training or asynchronous multi-machine training. When used to train locally on one machine, variables are not mirrored, instead they are placed on the CPU and operations are replicated across all local GPUs.
parameter_server_strategy = tf.distribute.experimental.ParameterServerStrategy(tf.distribute.cluster_resolver.TFConfigClusterResolver(),
variable_partitioner=variable_partitioner)
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(strategy)TPUStrategy : Supports TensorFlow training on Tensor Processing Units (TPUs). TPUStrategy is same as the MirroredStrategy which implements synchronous distributed training. TPUs provide their own implementation of efficient all-reduce and other collective operations across multiple TPU cores
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(
tpu=tpu_address)
tf.config.experimental_connect_to_cluster(cluster_resolver)
tf.tpu.experimental.initialize_tpu_system(cluster_resolver)
tpu_strategy = tf.distribute.TPUStrategy(cluster_resolver)CentralStorageStrategy: Supports synchronous training and variables are not mirrored, instead they are placed on the CPU and operations are replicated across all local GPUs. If there is only one GPU, all variables and operations will be placed on that GPU.
central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()Distributed training with Keras using MNIST dataset
# strategy = mirrored_strategy or multi_worker_mirrored_strategy or parameter_server_strategy or tpu_strategy or central_storage_strategy
import tensorflow_datasets as tfds
import tensorflow as tf
import os
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
strategy = tf.distribute.MirroredStrategy()
# You can also do info.splits.total_num_examples to get the total number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True)]
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))Tutorial #1: Distribution Strategy API with Estimator
In this example, we will use the MirroredStrategy with the Estimator class to train and evaluate a simple TensorFlow model. This example is based on the official TensorFlow documentation.
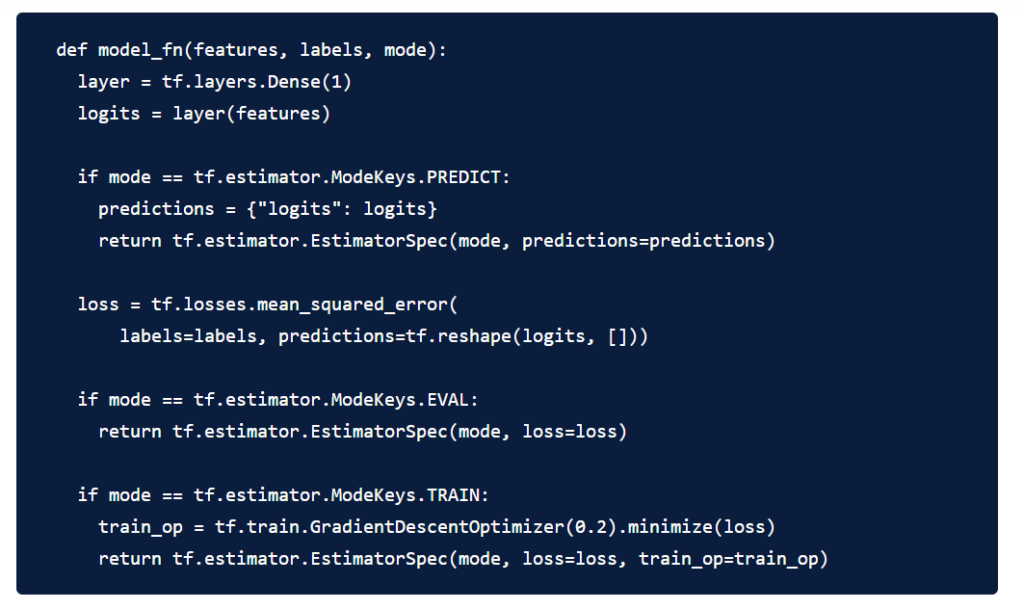
Define a simple input function to feed data for training this model.

Now that we have a model function and input function defined, we can define the estimator. To use MirroredStrategy, all we need to do is:
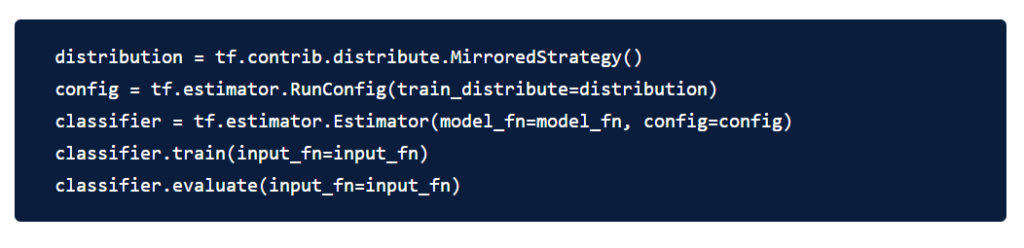
This change will now configure Estimator to run on all GPUs on your machine.
Distributed TensorFlow using Horovod
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet.
The data-parallel distributed training paradigm under Horovod is straightforward:
1. Run multiple copies of the training script and each copy:
– Reads a chunk of the data
– Runs it through the model
– Computes model updates (gradients)
2. Average gradients among those multiple copies
3. Update the model
4. Repeat (from Step 1)
Tutorial #2: Use Horovod in TensorFlow with Estimators
This tutorial is based on an article by Jordi Torres
1. Import Horovod:

2. Horovod must be initialized before starting:

3. Pin a server GPU to be used by this process
With the typical setup of one GPU per process, this can be set to local rank. In that case, the first process on the server will be allocated the first GPU, the second process will be allocated the second GPU and so forth.
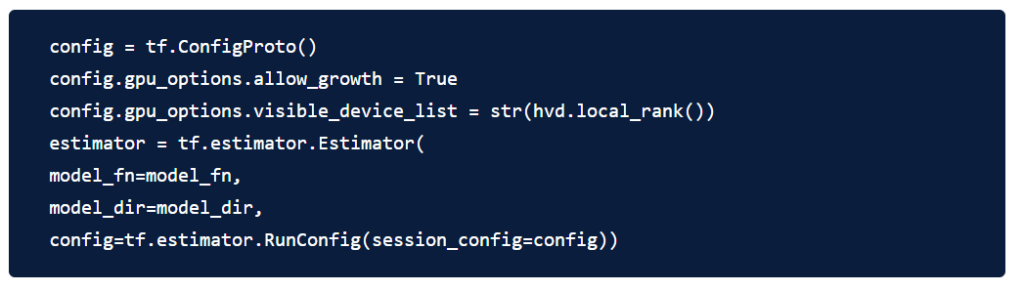
4. Wrap optimizer in hvd.DistributedOptimizer.
The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients.
5. Add hvd.BroadcastGlobalVariablesHook(0)
This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint. Alternatively, if you’re not using MonitoredTrainingSession, you can simply execute the hvd.broadcast_global_variables op after global variables have been initialized.
6. Modify code
Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them.

7. Run Horovod
To run on a machine with 4 GPUs we will use mpirun to run the python script:

To run on 4 machines with 4 GPUs each (16 GPUs):





