Convolutional Neural Networks (CNNs) were originally designed for deep learning computer vision tasks, but they have proven highly useful for Natural Language Processing (NLP) tasks as well. A primary use case is sentence classification. Today, CNNs are a state-of-the-art technique helping to automatically classify text strings by emotional sentiment, object categories, urgency, priority, or other characteristics.
What is Natural Language Processing
Natural language processing is the practice of automatically processing textual information and deriving meaning from it. Some common uses of NLP are:
– Sentiment analysis – processing text such as social media postings or reviews to identify the emotion behind them, or whether they are positive, negative or neutral.
– Natural language search – issuing a query and obtaining search results relevant to the query.
– Named entity recognition – recognizing names of people, places, or concepts within a text.
– Natural language generation – generating text, from summarization to automated image captions to chatbots.
What is Sentence Classification
The vast majority of the world’s textual content is unstructured, making automated classification an important task. Sentence classification involves taking segments of text of various lengths and assigning them with meaningful labels, such as:
– Sentiment also popularly known as Sentiment Analysis
– Subjects or topics also popularly known as Topic Modelling
– Urgency or priority
– Style, complexity, or language
Traditionally, automated sentence classification was carried out by bag-of-words (BOW) models such as Naive Bayes or Support Vector Machines. State-of-the-art models rely on text classification using neural networks, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
What are Convolutional Neural Networks and their effectiveness for NLP
Convolutional Neural Networks (CNNs) were originally designed to perform deep learning for computer vision tasks, and have proven highly effective. They use the concept of a “convolution”, a sliding window or “filter” that passes over the image, identifying important features and analyzing them one at a time, then reducing them down to their essential characteristics, and repeating the process.
It turned out that this approach works well for NLP as well. In 2014, Yoon Kim published the original research paper on using CNNs for text classification. He tested four CNN variations, and showed CNN models could outperform previous approaches for several classification tasks.
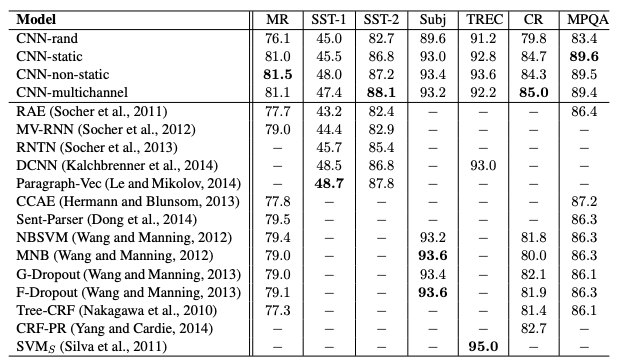
Kim tested the classification problems with robust datasets (indicated as acronyms at the top of the table). Indeed, these are some of the common mainstream uses of CNN for sentence classification today:
– Classifying positive/negative movie reviews
– Classifying sentences as subjective or objective
– Classifying questions into types (about a person, location, numerical information, etc.)
– Identifying positive/negative product reviews
– Detecting opinion polarity
Of course, CNNs are not limited to these cases and can be used for any single- or multi-label classification problem on textual inputs.
How Convolutional Networks perform text classification
Below is a typical CNN architecture used for text processing. It starts with an input sentence broken up into words or word embeddings: low-dimensional representations generated by models like word2vec or GloVe.
Words are broken up into features and are fed into a convolutional layer. The results of the convolution are “pooled” or aggregated to a representative number. This number is fed to a fully connected neural structure, which makes a classification decision based on the weights assigned to each feature within the text.
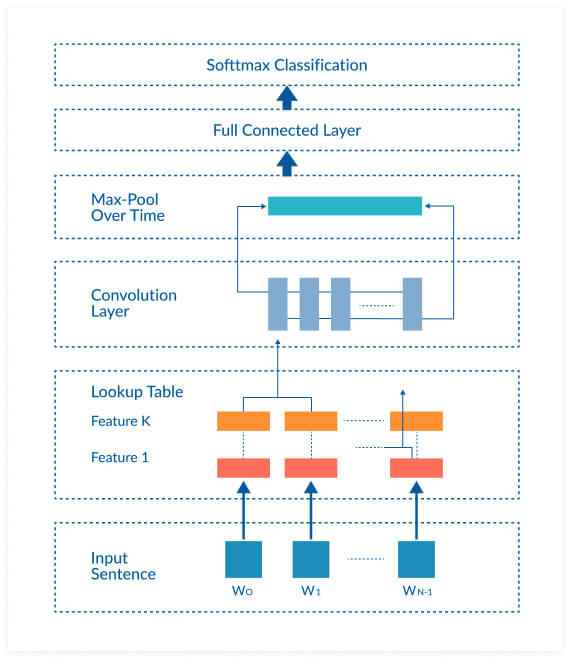
Example of convolutional process on text vectors
In a CNN, text is organised into a matrix, with each row representing a word embedding, a word, or a character. The CNN’s convolutional layer “scans” the text like it would an image, breaks it down into features, and judges whether each feature matches the relevant label or not.
The following image illustrates how the convolutional “filter” slides over a sentence, two words at a time. It computes an element-wise product of the weights of each word, multiplied by the weights assigned to the convolutional filter.
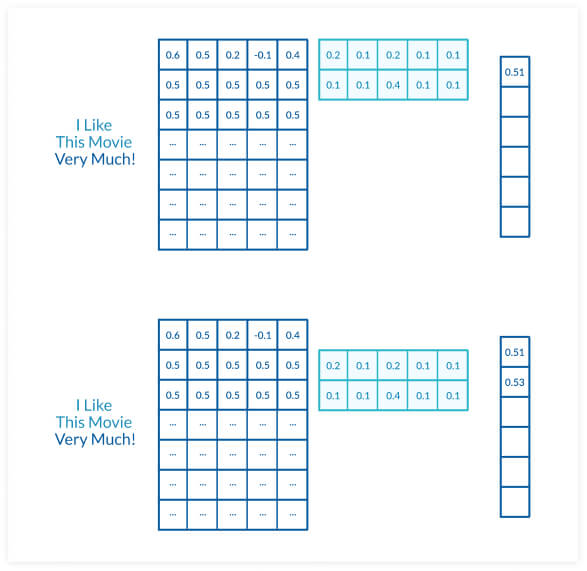
The sum of the products is taken as a representation of the current textual feature – 0.51 and 0.53 in the example. This is the “pooling” stage, reducing the dimensionality of the word features and retaining only a simple probability score that reflects how likely they are to match a label.
At the final stage, these scores are the inputs to a fully connected neural layer. The “fully connected” part of the CNN network goes through its own backpropagation process, to determine the most accurate weights. Each neuron receives weights that prioritize the most appropriate label – for example, “positive sentiment” or “negative sentiment”. Finally, the neurons “vote” on each of the labels, and the winner of that vote is the classification decision.