
Modern Computer Vision technology, based on AI and deep learning methods, has evolved dramatically in the past decade. Today it is used for applications like image classification, face recognition, identifying objects in images, video analysis and classification, and image processing in robots and autonomous vehicles.
Many computer vision tasks require intelligent segmentation of an image, to understand what is in the image and enable easier analysis of each part. Today’s image segmentation techniques use models of deep learning for computer vision to understand, at a level unimaginable only a decade ago, exactly which real-world object is represented by each pixel of an image.
Deep learning can learn patterns in visual inputs in order to predict object classes that make up an image. The main deep learning architecture used for image processing is a Convolutional Neural Network (CNN), or specific CNN frameworks like AlexNet, VGG, Inception, and ResNet. Models of deep learning for computer vision are typically trained and executed on specialized graphics processing units (GPUs) to reduce computation time.
What is Image Segmentation?
Image segmentation is a critical process in computer vision. It involves dividing a visual input into segments to simplify image analysis. Segments represent objects or parts of objects, and comprise sets of pixels, or “super-pixels”. Image segmentation sorts pixels into larger components, eliminating the need to consider individual pixels as units of observation. There are three levels of image analysis:
Classification – categorizing the entire image into a class such as “people”, “animals”, “outdoors”
Object detection – detecting objects within an image and drawing a rectangle around them, for example, a person or a sheep.
Segmentation – identifying parts of the image and understanding what object they belong to. Segmentation lays the basis for performing object detection and classification.

Semantic Segmentation vs. Instance Segmentation
Within the segmentation process itself, there are two levels of granularity:
Semantic segmentation—classifies all the pixels of an image into meaningful classes of objects. These classes are “semantically interpretable” and correspond to real-world categories. For instance, you could isolate all the pixels associated with a cat and color them green. This is also known as dense prediction because it predicts the meaning of each pixel.
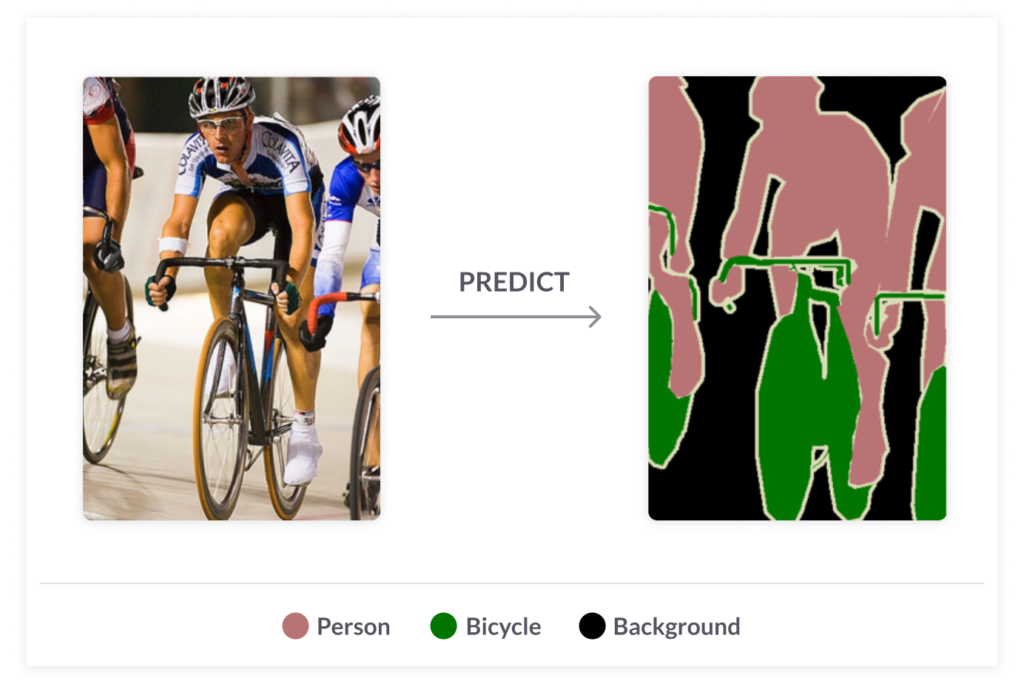
Instance segmentation—identifies each instance of each object in an image. It differs from semantic segmentation in that it doesn’t categorize every pixel. If there are three cars in an image, semantic segmentation classifies all the cars as one instance, while instance segmentation identifies each individual car.
Old-School Image Segmentation Methods
There are additional image segmentation techniques that were commonly used in the past but are less efficient than their deep learning counterparts because they use rigid algorithms and require human intervention and expertise. These include:
Thresholding—divides an image into a foreground and background. A specified threshold value separates pixels into one of two levels to isolate objects. Thresholding converts grayscale images into binary images or distinguishes the lighter and darker pixels of a color image.
K-means clustering—an algorithm identifies groups in the data, with the variable K representing the number of groups. The algorithm assigns each data point (or pixel) to one of the groups based on feature similarity. Rather than analyzing predefined groups, clustering works iteratively to organically form groups.
Histogram-based image segmentation—uses a histogram to group pixels based on “gray levels”. Simple images consist of an object and a background. The background is usually one gray level and is the larger entity. Thus, a large peak represents the background gray level in the histogram. A smaller peak represents the object, which is another gray level.
Edge detection—identifies sharp changes or discontinuities in brightness. Edge detection usually involves arranging points of discontinuity into curved line segments, or edges. For example, the border between a block of red and a block of blue.
How Deep Learning Powers Image Segmentation Methods
Modern image segmentation techniques are powered by deep learning technology. Here are several deep learning architectures used for segmentation:
Convolutional Neural Networks (CNNs) Image segmentation with CNN involves feeding segments of an image as input to a convolutional neural network, which labels the pixels. The CNN cannot process the whole image at once. It scans the image, looking at a small “filter” of several pixels each time until it has mapped the entire image. To learn more see our in-depth guide about Convolutional Neural Networks.
Fully Convolutional Networks (FCNs) Traditional CNNs have fully-connected layers, which can’t manage different input sizes. FCNs use convolutional layers to process varying input sizes and can work faster. The final output layer has a large receptive field and corresponds to the height and width of the image, while the number of channels corresponds to the number of classes. The convolutional layers classify every pixel to determine the context of the image, including the location of objects.
Ensemble learning Synthesizes the results of two or more related analytical models into a single spread. Ensemble learning can improve prediction accuracy and reduce generalization error. This enables accurate classification and segmentation of images. Segmentation via ensemble learning attempts to generate a set of weak base-learners which classify parts of the image, and combine their output, instead of trying to create one single optimal learner.
DeepLab One main motivation for DeepLab is to perform image segmentation while helping control signal decimation—reducing the number of samples and the amount of data that the network must process. Another motivation is to enable multi-scale contextual feature learning—aggregating features from images at different scales. DeepLab uses an ImageNet pre-trained residual neural network (ResNet) for feature extraction. DeepLab uses atrous (dilated) convolutions instead of regular convolutions. The varying dilation rates of each convolution enable the ResNet block to capture multi-scale contextual information. DeepLab is comprised of three components:
Atrous convolutions—with a factor that expands or contracts the convolutional filter’s field of view.
ResNet—a deep convolutional network (DCNN) from Microsoft. It provides a framework that enables training thousands of layers while maintaining performance. The powerful representational ability of ResNet boosts computer vision applications like object detection and face recognition.
Atrous spatial pyramid pooling (ASPP)—provides multi-scale information. It uses a set of atrous convolutions with varying dilation rates to capture long-range context. ASPP also uses global average pooling (GAP) to incorporate image-level features and add global context information.
SegNet neural network An architecture based on deep encoders and decoders, also known as semantic pixel-wise segmentation. It involves encoding the input image into low dimensions and then recovering it with orientation invariance capabilities in the decoder. This generates a segmented image at the decoder end
Image Segmentation Applications
Image segmentation helps determine the relations between objects, as well as the context of objects in an image. Applications include face recognition, number plate identification, and satellite image analysis. Industries like retail and fashion use image segmentation, for example, in image-based searches. Autonomous vehicles use it to understand their surroundings.
Object Detection and Face Detection
These applications involve identifying object instances of a specific class in a digital image. Semantic objects can be classified into classes like human faces, cars, buildings, or cats.
Face detection—a type of object-class detection with many applications, including biometrics and autofocus features in digital cameras. Algorithms detect and verify the presence of facial features. For example, eyes appear as valleys in a gray-level image.
Medical imaging—extracts clinically relevant information from medical images. For example, radiologists may use machine learning to augment analysis, by segmenting an image into different organs, tissue types, or disease symptoms. This can reduce the time it takes to run diagnostic tests.
Machine vision—applications that capture and process images to provide operational guidance to devices. This includes both industrial and non-industrial applications. Machine vision systems use digital sensors in specialized cameras that allow computer hardware and software to measure, process, and analyze images. For example, an inspection system photographs soda bottles and then analyzes the images according to pass-fail criteria to determine if the bottles are properly filled.
Video Surveillance—video tracking and moving object tracking
This involves locating a moving object in video footage. Uses include security and surveillance, traffic control, human-computer interaction, and video editing.
Self-driving vehicles—autonomous cars must be able to perceive and understand their environment in order to drive safely. Relevant classes of objects include other vehicles, buildings, and pedestrians. Semantic segmentation enables self-driving cars to recognize which areas in an image are safe to drive.
Iris recognition—a form of biometric identification that recognizes the complex patterns of an iris. It uses automated pattern recognition to analyze video images of a person’s eye.
Face recognition—identifies an individual in a frame from a video source. This technology compares selected facial features from an input image with faces in a database.
Retail Image Recognition
This application provides retailers with an understanding of the layout of goods on the shelf. Algorithms process product data in real time to detect whether goods are present or absent on the shelf. If a product is absent, they can identify the cause, alert the merchandiser, and recommend solutions for the corresponding part of the supply chain.
Example and Code for Image Segmentation : https://indiantechwarrior.com/tutorial-on-tensorflow-image-segmentation/




