
TensorFlow provides powerful tools for building, customizing and optimizing Convolutional Neural Networks (CNN) used to classify and understand image data. An essential part of the CNN architecture is the pooling stage, in which feature data collected in the convolution layers are downsampled or “pooled”, to extract their essential information.
It’s important to note that while pooling is commonly used in CNN, some convolutional architectures, such as ResNet, do not have separate pooling layers, and use convolutional layers to extract pertinent feature information and pass it forward.
Pooling Layers and their Role in CNN Image Classification
The purpose of pooling layers in CNN is to reduce or downsample the dimensionality of the input image. Pooling layers make feature detection independent of noise and small changes like image rotation or tilting. This property is known as “spatial variance.”
Pooling is based on a “sliding window” concept. It applies a statistical function over the values within a specific sized window, known as the convolution filter or kernel.
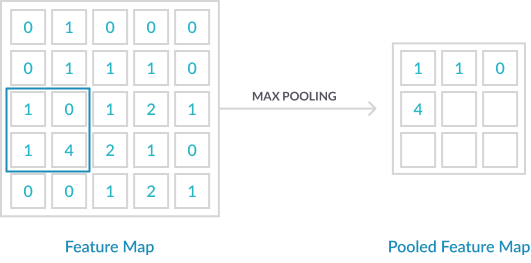
The most commonly used type is max pooling. Max Pooling take the maximum value within the convolution filter. The diagram below shows some max pooling in action.
In the diagram above, the colored boxes represent a max pooling function with a sliding window (filter size) of 2×2. The simple maximum value is taken from each window to the output feature map. In other words, the maximum value in the blue box is 3. This value will represent the four nodes within the blue box. The same applies to the green and the red box.
Pooling in small images with a small number of features can help prevent overfitting. In large images, pooling can help avoid a huge number of dimensions. Optimization complexity grows exponentially with the growth of the dimension. Thus you will end up with extremely slow convergence which may cause overfitting.
The following image provides an excellent demonstration of the value of max pooling. In each image, the cheetah is presented in different angles.

Max pooling helps the convolutional neural network to recognize the cheetah despite all of these changes. After all, this is the same cheetah. Let’s assume the cheetah’s tear line feature is represented by the value 4 in the feature map obtained from the convolution operation.
It doesn’t matter if the value 4 appears in a cell of 4 x 2 or a cell of 3 x1, we still get the same maximum value from that cell after a max pooling operation. This process is what provides the convolutional neural network with the “spatial variance” capability.
Lets Calculate the output dimensions of Max pooling layer
Max Pooling Layer = ((Input – K)/S +1) X D
Input Dimensions – [ None 85 64 128 ]
Kernel [3 4 128]
Max pooling calculations (H) = ((85-3)/2 +1 X D = 42 X 128
Max pooling calculations (W) = ((64-4)/2 +1 X D = 31 X 128
Output Dimensions – [None 42 31 128]
Using the tf.layers.MaxPooling function
The tf.layers module provides a high-level API that makes it easy to construct a neural network. It provides three methods for the max pooling operation:
layers.MaxPooling1Dfor 1D inputslayers.MaxPooling2Dfor 2D inputs (e.g. images)layers.MaxPooling3Dfor 3D inputs (e.g. volumes). To learn about tf.nn.max_pool(), which gives you full control over how the pooling layer is structured see the following section
Let’s review the arguments of the MaxPooling1D(), MaxPooling2D() and MaxPooling3D functions:`

Using tf.nn.max_pool for Full Control Over the Pooling Layer
tf.nn.max_pool() is a lower-level function that provides more control over the details of the maxpool operation. Here is the full signature of the function:

Let’s review the arguments of the tf.nn.max_pool() function:





