The world around us is full of detail, and we intuitively understand the difference between natural and fake objects. The sheer complexity of an individual voice or face makes it almost unthinkable to recreate an accurate representation. So how do you create an image, voice, or text from scratch, without anyone noticing that it is artificial? You can do it by using two neural networks pitted against each other, challenging each other to understand what makes objects appear realistic.
In this article, we’ll explain the concept of Generative Adversarial Network (GAN), how to use GAN models in computer vision.
What Is a GAN?
A Generative Adversarial Network (GAN) is a deep learning (DL) architecture comprising two competing neural networks within the framework of a zero-sum game. It is a form of unsupervised learning first introduced by Ian J. Goodfellow and his colleagues in 2014. Since then, this technology has seen rapid advances.
Generative adversarial networks, like other generative models, can artificially generate artifacts, such as images, video, and audio, which resemble human-generated artifacts. The objective is to produce a complex output from a simple input, with the highest possible level of accuracy. For example, translating a few random numbers into a realistic image of a face.
GAN works by training neural networks against each other. One network creates a fake artifact, and the other network attempts to distinguish the fake object from the real object. At first, there is a clear difference between the real object and the fake, but as the dual network trains itself over time, it learns to create more realistic artifacts, until the fake artifacts manage to “fool” the system and are taken to be real.
Examples of GAN Applications
While generative adversarial networks have fewer business-critical applications when compared to other deep learning models, you can use GAN to create or enhance objects for a variety of artistic applications. For example, you can convert black-and-white images to color and increase their resolution, or train a bot to author a blog post.
Notable applications of GAN include:
Data augmentation—you can train a GAN to generate new sample images from your data, augmenting your dataset. Once your GAN is mature, you can use the images it generates to help train other networks.
Text-to-image generation—uses include producing films or comics by automatically generating a sequence of images based on a text input.
Generating faces—NVIDIA researchers trained a GAN using over 200,000 sample images of celebrity faces, which was then able to generate photorealistic images of people who have never actually existed.
Image-to-image translation—the GAN learns to map a pattern from input images onto output images. For example, you can use it to convert an image into the style of a famous painter like Van Gogh or Monet or to transform a horse into a zebra.
E-Commerce and industrial design—you can use the GAN for suggesting merchandise and creating new 3D products based on product data. For example, you can generate new styles of clothes to help meet consumer demand.
How Do GANs Work?
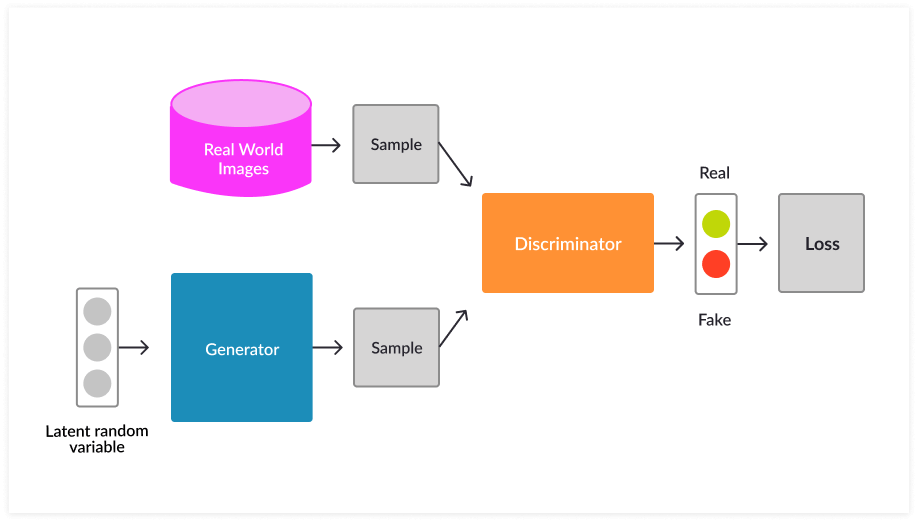
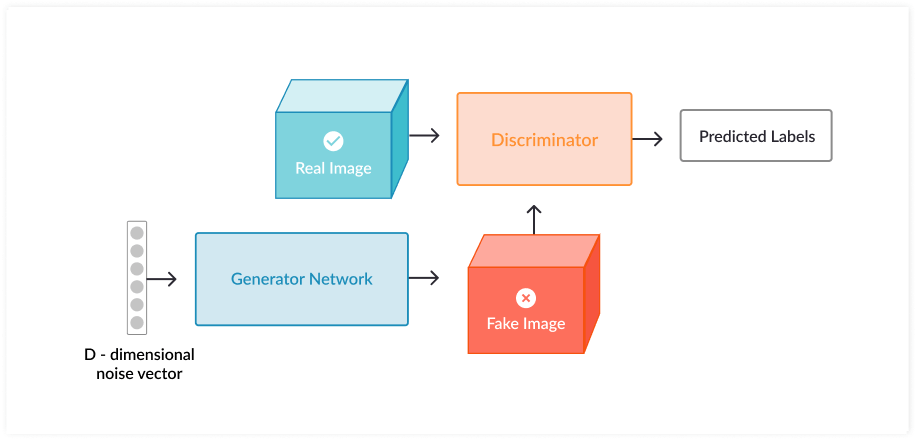
The two neural networks that make up the GAN are called the generator and the discriminator. The GAN generator creates new data instances and the discriminator evaluates their authenticity, or whether they belong in the dataset. The GAN discriminator is a fully connected neural network that classifies whether an image is real (1) or generated (0). To establish a generative adversarial network, you first need to identify your desired end output and provide an initial training dataset. The GAN starts by learning on a simple distribution of points in two dimensions, and with training will eventually be able to mimic any distribution of data.
While your main training objective is to train the generator, both networks benefit from the training loop. In a process known as backpropagation, each network trains and reinforces the other until the discriminator can no longer distinguish between the real and the generated images.
In the first phase, you need to train the discriminator to identify probability distribution. You can use images from the MNIST database along with the generated images to train the discriminator. Once the discriminator has achieved a basic level of maturity, you can start training the generator against the discriminator. The generator learns to map a random data distribution from a latent sample (a series of randomly generated numbers). You can also set the discriminator to non-trainable while training the generator.
For a typical example of a GAN process, you can feed a D-dimensional noise vector taken from the latent sample into the generator, which then converts it into an image. The discriminator then processes and classifies it, and the feedback helps the generator improve its capabilities. A crucial advantage of GAN is its randomness, which allows it to generate an entirely new object, rather than simply creating an exact replica of the input.
Popular Types of GANs
Since generative adversarial networks were first proposed, new designs have emerged that build on the basic GAN architecture. These new architectures improve on the accuracy of object generation or address specific design needs.
DCGAN
Convolutional neural networks (CNNs) are typically used for supervised computer vision tasks. Deep convolutional generative adversarial networks (DCGANs), which were introduced in a 2015 paper by Alec Radford, Luke Metz, and Soumith Chintala, incorporate convolutional networks into an unsupervised deep learning framework, and it is the first instance in which CNNs have achieved impressive results when used within a GAN.
This model involves major architectural changes, including the replacement of pooling layers with strided convolutions and fractional-strided convolutions; the use of batch normalization for both networks; and the removal of fully connected hidden layers. These changes stabilize training, allow for deeper generative models, and prevent mode collapse and internal covariate shift.
StyleGan
This model, based on a style mixing algorithm, enables a better understanding of generated outputs and produces more authentic-looking images than previous models. It also offers more control over specific features. The style-based generator generates the images gradually, in progressive layers, starting with low-resolution outputs and building up to high-resolution. For example, the coarse level may determine pose and general outline, the middle level may determine facial expressions and hairstyle, and the fine level may determine microfeatures.
The architecture includes a mapping network made up of eight fully connected layers, with an output equal in size to the input layer. The mapping network encodes the input vector into an intermediate vector that can control various features. An adaptive instance normalization (AdaIN) style module converts the encoded information from the mapping network into a generated image.
BigGan
The latest development in GAN image generation, this model is distinguished by the sheer computing power that supports it. It produces images with unprecedented high fidelity and a low variety gap. To illustrate this point, BigGAN has achieved an Inception Score of 166.3, compared with the previous record of 52.52.
The success of BigGAN boils down to computational factors, rather than algorithmic ones. By adding more nodes to the neural network, you can increase complexity while training the system to pick up subtle differences in texture, allowing it to recreate realistic skin, hair, or water. However, this type of architecture is not yet viable for common use. In his experiment, Ph.D. student Andrew Brock used Google’s Tensor Processing Units (TPUs), which consume large amounts of energy.
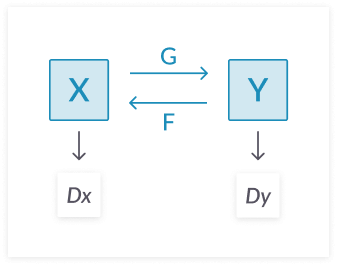
CycleGAN:
This was first proposed by Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. You can apply cycle generative adversarial networks (CycleGAN) to various image-to-image translation use-cases. For example, you can convert a photograph into a painting, or a painting into a photograph.
The architecture consists of two adversarial mappings: G : X -> Y and F : Y -> X. G generates outputs from X, and Domain Y evaluates if they are real or fake. F generates outputs from Y, and Domain X checks if they are real or fake. The GAN tries to minimize the cyclic loss incurred when translating an input from X to Y and back again.
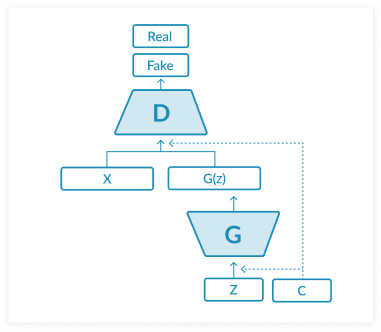
Conditional GAN:
A conditional generative adversarial network (CGAN), introduced by Mehdi Mirza and Simon Osindero, involves applying conditional settings to the GAN. Both the generator and discriminator are conditioned on auxiliary information, giving the user greater control over the output.
In the CGAN architecture, the noise vector input is embedded with a class label, typically a one-hot encoded vector. The generator has an added Y parameter for generating the corresponding data, and the input is labeled to help the discriminator distinguish between the real and fake data. This allows the model to learn multimodal mapping of outputs from inputs with reference to contextual information. For example, conditioning MNIST images on class labels.