
Fully connected layers are an essential component of Convolutional Neural Networks (CNNs), which have been proven very successful in recognizing and classifying images for computer vision.
The CNN process begins with convolution and pooling, breaking down the image into features, and analyzing them independently. The result of this process feeds into a fully connected neural network structure that drives the final classification decision.
This article provides an in-depth review of CNNs, how their architecture works, and how it applies to real-world applications of deep learning for computer vision.
What Is a Convolutional Neural Network?
A Convolutional Neural Network (CNN) is a type of neural network that specializes in image recognition and computer vision tasks.
CNNs have two main parts:
– A convolution/pooling mechanism that breaks up the image into features and analyzes them
– A fully connected layer that takes the output of convolution/pooling and predicts the best label to describe the image
Convolutional Neural Networks vs Fully Connected Neural Networks
Fully connected layers in a CNN are not to be confused with fully connected neural networks – the classic neural network architecture, in which all neurons connect to all neurons in the next layer. Convolutional neural networks enable deep learning for computer vision. The classic neural network architecture was found to be inefficient for computer vision tasks. Images represent a large input for a neural network (they can have hundreds or thousands of pixels and up to 3 color channels). In a classic fully connected network, this requires a huge number of connections and network parameters.
A convolutional neural network leverages the fact that an image is composed of smaller details, or features, and creates a mechanism for analyzing each feature in isolation, which informs a decision about the image as a whole.
As part of the convolutional network, there is also a fully connected layer that takes the end result of the convolution/pooling process and reaches a classification decision.
CNN Architecture: Types of Layers
Convolutional Neural Networks have several types of layers:
Convolutional layer – a “filter” passes over the image, scanning a few pixels at a time and creating a feature map that predicts the class to which each feature belongs.
Pooling layer (downsampling) – reduces the amount of information in each feature obtained in the convolutional layer while maintaining the most important information (there are usually several rounds of convolution and pooling).
Fully connected input layer (flatten) – takes the output of the previous layers, “flattens” them and turns them into a single vector that can be an input for the next stage.
The first fully connected layer – takes the inputs from the feature analysis and applies weights to predict the correct label.
Fully connected output layer – gives the final probabilities for each label.
The CNN Architecture is used in Object Detection and Image Classification model development. If you want to go deeper into how these models work and are implemented then Coding exercises with live examples can be accessed at Code Implementation of Object Detection using CNN.
Below is an example showing the layers needed to process an image of a written digit, with the number of pixels processed in every stage. This is a very simple image, larger and more complex images would require more convolutional/pooling layers.
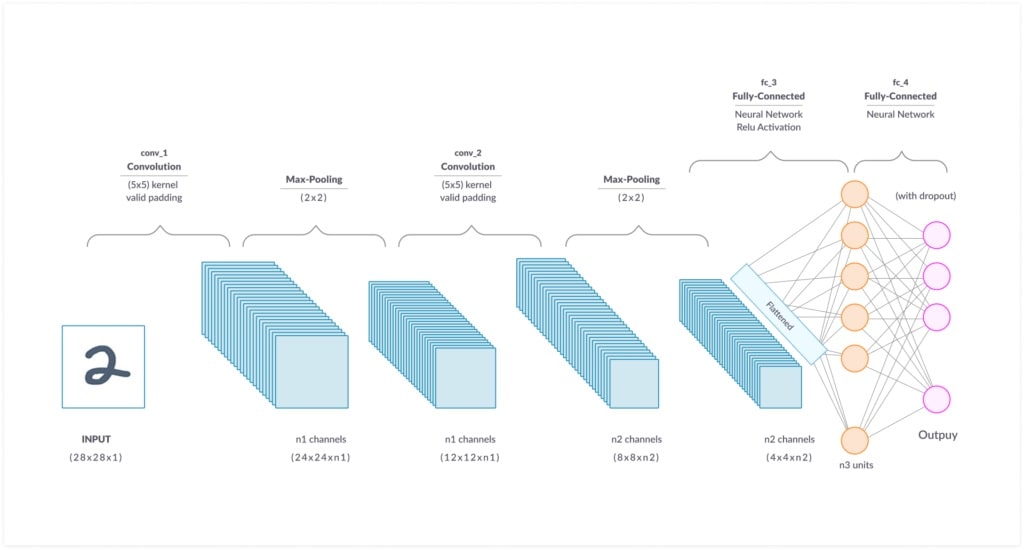
Fully Connected Layer
Fully Connected Layer (also known as Hidden Layer) is the last layer in the convolutional neural network. This layer is a combination of Affine function and Non-Linear function.
Affine Function y = Wx + b
Non-Linear Function Sigmoid, TanH and ReLu
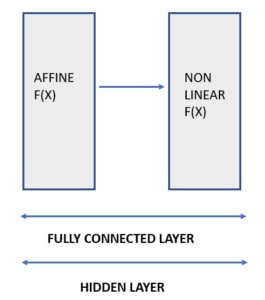
Fully Connected layer takes input from Flatten Layer which is a one-dimensional layer (1D Layer). The data coming from Flatten Layer is passed first to Affine function and then to Non-Linear function. The combination of 1 Affine function and 1 Non-Linear Function is called as 1 FC (Fully Connected) or 1 Hidden Layer.
We can add multiple such layers based on the depth to which we want to take our classification model. Note that this entirely depends on the training dataset. Output from the final hidden layer is sent to Softmax or Sigmoid function for probability distribution over final set of total number of classes.

The combination of Flatten Layer with Fully Connected Layer and Softmax Layer comes under Classification section of Deep Neural Network.
If we take a look at the complete neural network, we will see that the initial layers of convolutional neural network comprises of:
- Convolutional Layer
- Pooling Layer
- Dropout Layer
These three together encompass feature selection(extraction). Based on the training data, one can add various permutation and combination of these layers.
The output layer in the convolutional neural network comprises of:
- Softmax or Sigmoid Layer
- Loss Calculation using Cross-entropy function
The final calculation of classes (Labels) is the list of all classes say for example 10 with probability associated with each class. The class with the highest probability is the final class of the input image. For those who are interested to build models using CNN, follow the code with explanation.





