
OpenCL is an open standard that is designed to utilize the computing power provided by GPUs for general computing applications. While both AMD and NVIDIA are major vendors of GPUs, NVIDIA is currently the most common GPU vendor for deep learning and cloud computing. NVIDIA’s CUDA toolkit works with all major deep learning frameworks, including TensorFlow, and has a large community support.
TensorFlow has limited support for OpenCL and AMD GPUs. You can build Tensorflow with SYCL (single source OpenCL) support. We’ll show you how to set this up in the article below, but performance might not be as good as with NVIDIA GPUs. Let us first understand few basics and alternative options available in market.
Picking a GPU for Deep Learning: CUDA vs OpenCL
What Is CUDA?
CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model created by NVIDIA and implemented by the graphics processing units (GPUs) that they produce. The NVIDIA CUDA Toolkit provides a development environment for creating high-performance GPU-accelerated applications. GPU-accelerated CUDA libraries enable acceleration across multiple domains such as linear algebra, image and video processing, deep learning and graph analytics.
Setting up GPU using CUDA for training in TensorFlow
There are multiple ways to do so, let me list them down :
1. Setting up CUDA_VISIBLE_DEVICES environment variable. When we setup environment variable CUDA_VISIBLE_DEVICES=”1″ this makes only one GPU available and by setting up CUDA_VISIBLE_DEVICES=”0,1″ makes devices 0 and 1 visible. Note if there are two GPU’s then first one is represented by “0” and second one by “1”. In python this is possible by running below code.
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0,1"2. By using below command and creating the graph.
with tf.device('/gpu:1'):
Your code here ...3. Using ConfigProto(). Note only for this case 0 is not the default value for GPU, counting starts from 1
config = tf.ConfigProto()
config.gpu_options.visible_device_list = "0,1"
with tf.Session(config) as sess:
Your code here..4. Using Tensorflow
tf.config.experimental.set_visible_devices(gpus[1], 'GPU')Example to show GPU vs CPU time consumption
from numba import cuda, njit
import numpy as np
# to measure exec time
from timeit import default_timer as timer
# normal function to run on cpu
def func(a):
for i in range(10000000):
a[i]+= 1
# function optimized to run on gpu
@njit
def func2(a):
for i in range(10000000):
a[i]+= 1
if __name__=="__main__":
n = 10000000
a = np.ones(n, dtype = np.float64)
b = np.ones(n, dtype = np.float32)
start = timer()
func(a)
print("without GPU:", timer()-start)
start = timer()
func2(a)
print("with GPU:", timer()-start)
Output :–
without GPU: 5.805383399999982
with GPU: 0.0957761299998765
What is OpenCL?
OpenCL, or Open Computing Language, is a framework designed for building applications that you can run across diverse computer systems. It is an open standard for developing cross-platform, parallel programming applications and has a number of open-source implementations.
OpenCL is designed for developers. Developers can use OpenCL to create applications that can be run on any device, regardless of manufacturer, processor specifications, graphics unit, or other hardware components. A developer can, for example, build an application on their Windows PC and the application will run equally well on an Android phone, Mac OS X computer, or any other parallel processing device. Provided, of course, that all of these devices support OpenCL and that the appropriate compiler and runtime library has been implemented.
CUDA and OpenCL offer two different interfaces for programming GPUs. OpenCL is an open standard that can be used to program CPUs, GPUs, and other devices from different vendors, while CUDA is specific to NVIDIA GPUs. Although OpenCL promises a portable language for GPU programming, its generality may entail a performance penalty.
With OpenCL, one can write programs that execute in parallel on different compute devices (such as CPUs and GPUs) from different vendors like AMD, Intel, ATI, Nvidia etc.
With OpenCL, you can:
- Leverage CPUs, GPUs along with other processors and DSPs to accelerate parallel computation
- Enable dramatic speedups for applications that are computationally intensive
- Create accelerated portable code across different devices and architectures
OpenCL Execution Model for HPC (High Performance Computing)
Write once and run on anything. Every vendor that provides OpenCL-compliant hardware also provides the tool that compile OpenCL code to run on the hardware. This means you can write your OpenCL routines once and compile them for any complaint device.
In other words, you code your vector routines once and then run them on any complaint processor. When you compile your application, Nvidia’s OpenCL compiler will produce PTX instructions. An IBM compiler for OpenCL will produce AltiVec instructions and Intel will produce SSE instructions. OpenCL provides advantages of Standard Vector Processing.
Parallel Programming – OpenCL provides full task parallelism not only just data-parallelism. In data parallelism each device receives the same instructions but operates on different sets of data. However, task parallelism allows OpenCL to configure different devices to perform different tasks and can operate on different data.
OpenCL framework as per the standards consist of 3 parts
- Platform – Makes it possible to access devices and form contexts
- Compiler – Builds programs that contains executable kernels called programs
- Runtime – Enable host application to send kernels and command queues to devices in the contexts.
OpenCL working group doesn’t provide any framework of its own. Instead vendors who produces OpenCL compliant devices releases framework as part of their SDK
OpenCL framework further divided into below Data Structures:
- Platform (SDK)
- Devices – Actual hardware (accelerator)
- Context – A virtual container which includes devices, kernels and command queue
- Program – These are collection of kernels and other functions similar to a dynamic library
- Kernels – To support parallelism, there is kernel which is the basic unit of executable code similar to a C function and can be data-parallel or task-parallel.
- Command Queues – These are queues in OpenCL that can be executed in-order or out-of-order
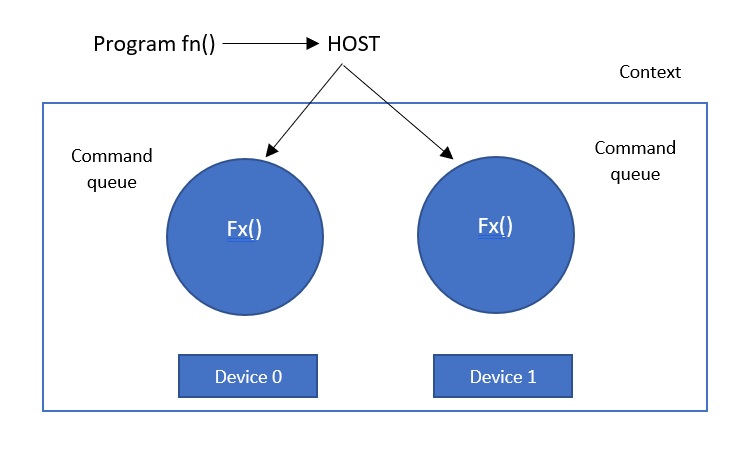
- myapplication.c function executes on the host
- device_code.cl kernel is created from the function file myapplication.c and send to the first device it finds. It reads the character from myapplication.c function into a character array, creates a program from the character array and complies the program. Then it construct device_code.cl kernel from that function.
Khronos has defined a cross-vendor , portable intermediate program representation called SPIR-V
Setup for OpenCL Application
Step 1 – Download the newest drivers that support OpenCL to your graphic card for the device. Usually, all graphics cards and CPUs from 2011 and later support OpenCL but it’s better to validate this by going to:
- Control Panel -> System & Security -> Display Adapters
- Control Panel -> System & Security -> Processors
You can refer the links below to install the drivers for major vendors:
- Nvidia – https://www.nvidia.com/download/index.aspx?lang=en-us
- AMD – https://www.amd.com/en/support
- Intel – https://www.intel.com/content/www/us/en/developer/articles/tool/opencl-drivers.html
Step 2 – Download the OpenCL implementation for the vendor that you have selected:
- Nvidia – http://developer.nvidia.com/object/cuda_download.html
- AMD – https://developer.amd.com/tools-and-sdks/
- Intel – https://www.intel.com/content/www/us/en/developer/tools/opencl-sdk/overview.html
CUDA vs. OpenCL for Deep Learning
An Nvidia GPU is the hardware that enables parallel computations, while CUDA is a software layer that provides an API for developers. The CUDA toolkit works with all major DL frameworks such as TensorFlow, Pytorch, Caffe, and CNTK. If you use NVIDIA GPUs, you will find support is widely available. If you program CUDA yourself, you will have access to support and advice if things go wrong. You will also find that most deep learning libraries have the best support for NVIDIA GPUs.
OpenCL runs on AMD GPUs and provides partial support for TensorFlow and PyTorch. If you want to develop new networks some details might be missing, which could prevent you from implementing the features you need.
The Tensor Cores are optimized processors provided in NVIDIA’s new Volta architecture. Tensor Cores provide superior compute performance for neural network architecture, and convolutional networks, however, their compute performance is not so high when it comes to word-level recurrent networks.
Does TensorFlow Support OpenCL?
To get OpenCL support to TensorFlow, you will have to set up an OpenCL version of TensorFlow using ComputeCpp. Codeplay has begun the process of adding OpenCL support to TensorFlow that can be achieved using SYCL. TensorFlow is built on top of the Eigen C++ library for linear algebra. Because Eigen uses C++ extensively, Codeplay has used SYCL (which enables Eigen-style C++ metaprogramming) to offload parts of Eigen to OpenCL devices.
Some of the GPU acceleration of TensorFlow could use OpenCL C libraries directly, such as for the BLAS components, or convolutions. SYCL is being used for the C++ tensor operations only which enables complex programmability of those tensor operations.
Quick Tutorial: Set Up and Run the TensorFlow OpenCL using SYCL
This tutorial will explain how to set up your machine to run the OpenCL version of TensorFlow using ComputeCpp, a SYCL implementation. The guide is based on the code from Codeplay.
1. Install AMDGPU open source unified graphics driver for Linux
wget --referer http://support.amd.com/ https://www2.ati.com/drivers/linux/ubuntu/amdgpu-pro-17.50-511655.tar.xz tar xf amdgpu-pro-17.50-511655.tar.xz ./amdgpu-pro-17.50-511655/amdgpu-pro-install --opencl=legacy --headless
2. Install the Intel NEO OpenCL GPU driver
wget https://github.com/intel/compute-runtime/releases/download/18.38.11535/intel-opencl_18.38.11535_amd64.deb sudo dpkg -i intel-opencl_18.38.11535_amd64.deb
3. Verify OpenCL installation
sudo apt-get update sudo apt-get install clinfo Clinfo
The output should list at least one platform and one device. The “Extensions” field of the device properties should include cl_khr_spir and/or cl_khr_il_program.
4. Build TensorFlow with SYCL Install dependency packages
sudo apt-get update sudo apt-get install git cmake gcc build-essential libpython-all-dev opencl-headers openjdk-8-jdk python python-dev python-pip zlib1g-dev pip install --user numpy==1.14.5 wheel==0.31.1 six==1.11.0 mock==2.0.0 enum34==1.1.6
5. Installation
– Register for an account on Codeplay’s developer website
– Download the following version: Ubuntu 16.04 > 64bit > computecpp-ce-1.1.1-ubuntu.16.04-64bit.tar.gz
tar -xf ComputeCpp-CE-1.1.1-Ubuntu.16.04-64bit.tar.gz sudo mv ComputeCpp-CE-1.1.1-Ubuntu-16.04-x86_64 /usr/local/computecpp export COMPUTECPP_TOOLKIT_PATH=/usr/local/computecpp export LD_LIBRARY_PATH+=:/usr/local/computecpp/lib /usr/local/computecpp/bin/computecpp_info
6. Install Bazel
wget https://github.com/bazelbuild/bazel/releases/download/0.16.0/bazel_0.16.0-linux-x86_64.deb sudo apt install -y bazel_0.16.0-linux-x86_64.deb bazel version
7. Build TensorFlow
git clone http://github.com/codeplaysoftware/tensorflow cd tensorflow
8. Bundle and install the wheel
bazel-bin/tensorflow/tools/pip_package/build_pip_package <path/to/output/folder> pip install --user <path/to/output/folder>/tensorflow-1.9.0-cp27-cp27mu-linux_x86_64.whl
9. Run a TensorFlow Benchmark
To verify the installation, you can execute some of the standard TensorFlow benchmarks. The example below shows how to run AlexNet
git clone http://github.com/tensorflow/benchmarks cd benchmarks git checkout f5d85aef2851881001130b28385795bc4c59fa38 python scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_batches=10 --local_parameter_device=sycl --device=sycl --batch_size=1 --forward_only=true --model=alexnet --data_format=NHWC




