
Advances in AI and deep learning have enabled the rapid evolution in the fields of computer vision and image analysis. This is all made possible by the emergence and progress of Convolutional Neural Networks (CNNs). Read on to learn more about what is a CNN, how many layers are used in a CNN and what is their purpose. Additionally, we will cover the ImageNet challenge and how it helped shape the most popular CNN architectures.
What Is a Convolutional Neural Network?
A Convolutional Neural Network (CNN) is a deep learning algorithm that can recognize and classify features in images for computer vision. It is a multi-layer neural network designed to analyze visual inputs and perform tasks such as image classification, segmentation and object detection, which can be useful for autonomous vehicles. CNNs can also be used for deep learning applications in healthcare, such as medical imaging.
There are two main parts to a CNN:
- A convolution tool that splits the various features of the image for analysis
- A fully connected layer that uses the output of the convolution layer to predict the best description for the image
Basic Convolutional Neural Network Architecture
CNN architecture is inspired by the organization and functionality of the visual cortex and designed to mimic the connectivity pattern of neurons within the human brain.
The neurons within a CNN are split into a three-dimensional structure, with each set of neurons analyzing a small region or feature of the image. In other words, each group of neurons specializes in identifying one part of the image. CNNs use the predictions from the layers to produce a final output that presents a vector of probability scores to represent the likelihood that a specific feature belongs to a certain class.
How a Convolutional Neural Network Works━The CNN layers
A CNN is composed of several kinds of layers:
Convolutional layer – creates a feature map to predict the class probabilities for each feature by applying a filter that scans the whole image, few pixels at a time.
Pooling layer (downsampling) – scales down the amount of information the convolutional layer generated for each feature and maintains the most essential information (the process of the convolutional and pooling layers usually repeats several times).
Fully connected input layer – “flattens” the outputs generated by previous layers to turn them into a single vector that can be used as an input for the next layer.
Fully connected layer – applies weights over the input generated by the feature analysis to predict an accurate label.
Fully connected output layer – generates the final probabilities to determine a class for the image.
Popular Convolutional Neural Network Architectures
The architecture of a CNN is a key factor in determining its performance and efficiency. The way in which the layers are structured, which elements are used in each layer and how they are designed will often affect the speed and accuracy with which it can perform various tasks.
The ImageNet Challenge
The ImageNet project is a visual database designed for use in the research of visual object recognition software. The ImageNet project has more than 14 million images specifically designed for training CNN in object detection, one million of which also provide bounding boxes for the use of networks such as YOLO.
Since 2010, the project hosts an annual contest called the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The contenders of the contest build software programs that attempt to correctly detect and classify objects and scenes within the given images. Currently, the challenge uses a cut down list of a thousand separate classes. When the annual ILSVRC competition began, a good classification rate was 25%, the first major leap in performance was achieved by a network called AlexNet in 2012, which dropped the classification rate by 10%. Over the next years, the error rates dropped to lower percentages and finally exceeded human capabilities.
Popular CNN Architectures
There are many popular CNN architectures, many of them gained recognition by achieving good results at the ILSVRC.
LeNet-5 (1998)
This 7-layer CNN classified digits, digitized 32×32 pixel greyscale input images. it was used by several banks to recognize the hand-written numbers on checks.
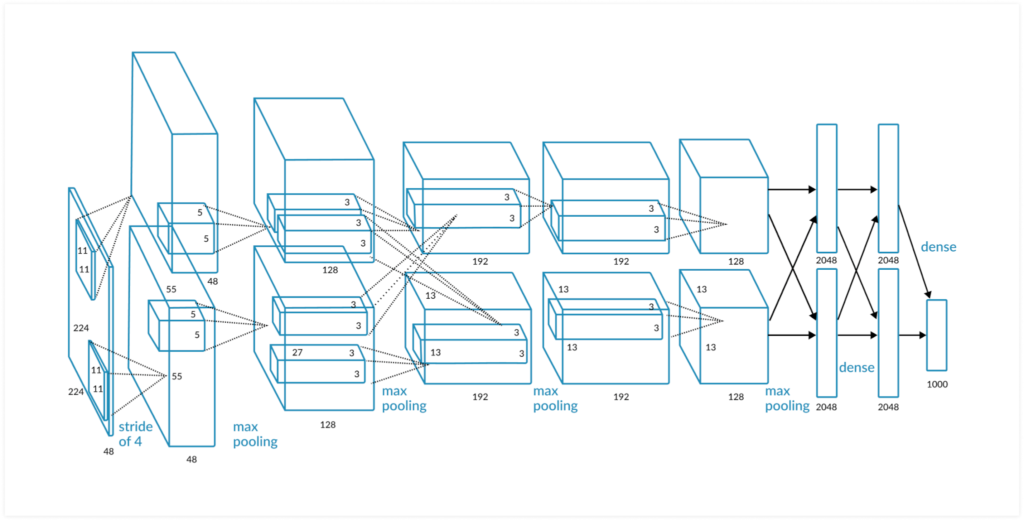
AlexNet (2012)
AlexNet is designed by SuperVision group, with a similar architecture to LeNet, but deeper━it has more filters per layer as well as stacked convolutional layers. It is composed of five convolutional layers followed by three fully connected layers. One of the most significant differences between AlexNet and other object detection algorithms is the use of ReLU for the non-linear part instead of Sigmond function or Tanh like traditional neural networks. AlexNet leverages ReLU’s faster training to make their algorithm faster.
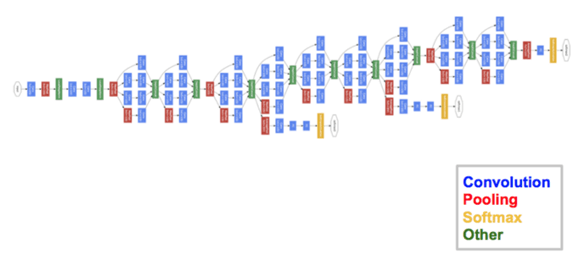
GoogleNet (2014)
Built with a CNN inspired by LetNet, the GoogleNet network, which is also named Inception V1, was made by a team at Google. GoogleNet was the winner of ILSVRC 2014 and achieved a top-5 error rate of less than 7%, which is close to the level of human performance. GoogleNet architecture consisted of a 22 layer deep CNN used a module based on small convolutions, called “inception module”, which used batch normalization, RMSprop and image to reduce the number of parameters from 60 million like in AlexNet to only 4 million.
VGGNet (2014)
VGGNet, the runner-up at the ILSVRC 2014, consisted of 16 convolutional layers. Similar to AlexNet, it used only 3×3 convolutions but added more filters. VGGNet trained on 4 GPUs for more than two weeks to achieve its performance. The problem with VGGNet is that it consists of 138 million parameters, 34.5 times more than GoogleNet, which makes it challenging to run.




