
Neural networks, inspired by the human brain, are increasingly being used in the classification of complex information and the use of CNNs and RNNs is especially promising. To learn about these two neural networks, often used in conjunction with each other, and how they are being developed to advance computer identification and the prediction of visual and audio inputs, read on.
What is a CNN?
A Convolutional Neural Network (CNN) is a multi-layer neural network used to analyze images for image classification, segmentation or object detection. CNNs work by reducing an image to its key features and using the combined probabilities of the identified features appearing together to determine a classification. One advantage that CNNs have over other classification algorithms is that they require fewer hyperparameters and less supervision.
What is a RNN?
A Recurrent Neural Network (RNN) is a multi-layer neural network, used to analyze sequential input, such as text, speech or videos, for classification and prediction purposes. RNNs work by evaluating sections of an input in comparison with the sections both before and after the section being classified through the use of weighted memory and feedback loops. RNNs are useful because they are not limited by the length of an input and can use temporal context to better predict meaning.
CNN vs RNN Comparison: Architecture and Applications
Although CNNs and RNNs are both neural networks and can process some of the same input types, they are structured differently and applied for different purposes.
CNN
CNNs are made up of three layer types—convolutional, pooling and fully-connected (FC). In the convolutional layers, an input is analyzed by a set of filters that output a feature map. This output is then sent to a pooling layer, which reduces the size of the feature map. This helps reduce the processing time by condensing the map to it’s most essential information. The convolutional and pooling processes are repeated several times, with the number of repeats depending on the network, after which the condensed feature map outputs are sent to a series of FC layers. These FC layers then flatten the maps together and compare the probabilities of each feature occurring in conjunction with the others, until the best classification is determined.
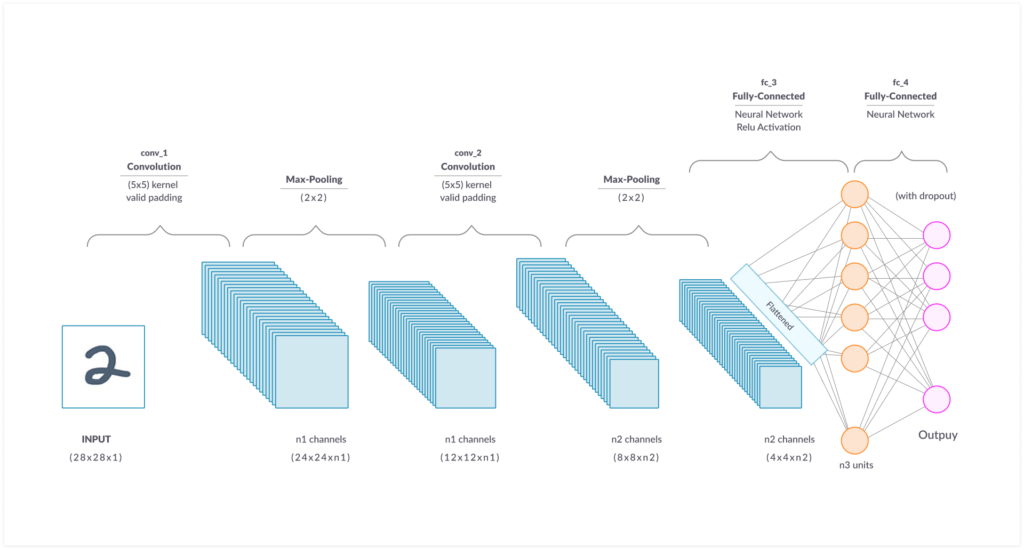
Illustration of CNN architecture layers
This architecture allows CNNs to learn the position and scale of features in a variety of images, making them especially good at the classification of hierarchical or spatial data and the extraction of unlabelled features. Unfortunately, this structure requires CNNs to only accept fixed-size inputs—and it only allows them to provide fixed-size outputs.
CNNs are currently being applied to several applications, including:
- Computer vision—medical image analysis, image recognition and face detection
- Natural Language Processing (NLP)—semantic parsing, sentence modeling and search query retrieval
- Drug discovery—the discovery of chemical features and prediction of medicinal benefits
RNN
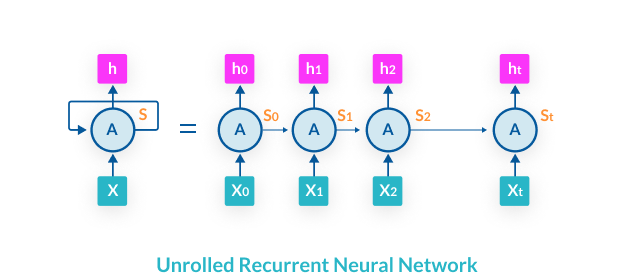
In a simple RNN, each input is evaluated on a single layer and an output is given. This can occur on a one-to-one, one-to-many, many-to-one or many-to-many input to output basis. As the RNN analyzes the sequential features of the input, an output is returned to the analysis step in a feedback loop, allowing the current feature to be analyzed in the context of the previous features. Since each step requires feedback from the previous step, RNNs are unable to take advantage of Massive Parallel Processing (MPP) as CNNs can.
When an RNN is trained, it is taught what weight to assign to each input feature, which then determines what information is passed back to the feedback loop according to gradient descent. This process, which creates the “short-term memory” of an RNN, is known as Backpropagation Through Time (BPTT).
RNNs are currently being applied to several applications, including:
- Temporal analysis—time-series anomaly detection and time-series prediction
- Computer vision—Image description, video tagging and video analysis
- NLP—Sentiment analysis, speech recognition, language modeling, machine translation and text generation
RNN CNN Hybrids
CNNs and RNNs are not mutually exclusive, as both can perform classification of image and text inputs, creating an opportunity to combine the two network types for increased effectiveness. This is especially true if the input to be classified is visually complex with added temporal characteristics that a CNN alone would be unable to process.
Typically, when these two network types are combined, sometimes referred to as a CRNN, inputs are first processed by CNN layers whose outputs are then fed to RNN layers. CNN Long Short-Term Memory (LSTM) architectures are particularly promising, as they facilitate analysis of inputs over longer periods than could be achieved with lower-level RNN architecture types.
Currently, these hybrid architectures are being explored for use in applications like video scene labeling, emotion detection or gesture recognition, video identification or gait recognition, and DNA sequence prediction.




