
Image classification algorithms, powered by Deep Learning (DL) Convolutional Neural Networks (CNN), fuel many advanced technologies and are a core research subject for many industries ranging from transportation to healthcare.
If you want to train a deep learning algorithm for image classification, you need to understand the different networks and algorithms available to you and decide which of them better is right for your needs. Read this article to learn why CNNs are a popular solution for image classification algorithms.
What Is Image Classification?
Image classification is the process of labeling images according to predefined categories. The process of image classification is based on supervised learning. An image classification model is fed a set of images within a specific category. Based on this set, the algorithm learns which class the test images belong to, and can then predict the correct class of future image inputs, and can even measure how accurate the predictions are.
This process introduces multiple challenges, including scale variation, viewpoint variation, intra-class variation, image deformation, image occlusion, illumination conditions and background clutter.
For example, if “dog” is one of the predefined categories, the image classification algorithm will recognize the image below is one of a dog and label it as such.
An image classification network will recognize that this is a dog
Deep Learning for Image Classification
Deep learning, a subset of Artificial Intelligence (AI), uses large datasets to recognize patterns within input images and produce meaningful classes with which to label the images. A common deep learning method for image classification is to train an Artificial Neural Network (ANN) to process input images and generate an output with a class for the image.
The challenge with deep learning for image classification is that it can take a long time to train artificial neural networks for this task. However, Convolutional Neural Networks (CNNs) excel at this type of task.
The Use of Convolutional Neural Networks for Image Classification
The CNN approach is based on the idea that the model function properly based on a local understanding of the image. It uses fewer parameters compared to a fully connected network by reusing the same parameter numerous times. While a fully connected network generates weights from each pixel on the image, a convolutional neural network generates just enough weights to scan a small area of the image at any given time.
This approach is beneficial for the training process━the fewer parameters within the network, the better it performs. Additionally, since the model requires less amount of data, it is also able to train faster.
When a CNN model is trained to classify an image, it searches for the features at their base level. For example, while a human might identify an elephant by its large ears or trunk, a computer will scan for curvatures of the boundaries of these features. Some object detection networks like YOLO achieve this by generating bounding boxes, which predict the presence and class of objects within the bounding boxes. Instance segmentation , a subset of image segmentation , takes this a step further and draws boundaries for each object, identifying its shape.
There are many applications for image classification with deep neural networks. CNNs can be embedded in the systems of autonomous cars to help the system recognize the surrounding of the car and classify objects to distinguish between ones that do not require any action, such as trees on the side of the road, and ones that do, such as civilians crossing the street.
Another use for CNNs is in advertising. For example, CNNs can easily scan a person’s Facebook page, classify fashion-related images and detect the person’s preferred style, allowing marketers to offer more relevant clothing advertisements. With a deep enough network, this principle can also be applied to identifying locations, such as pubs or malls, and hobbies like football or dancing.
ImageNet Classification with Deep Convolutional Neural Networks
This ImageNet challenge is hosted by the ImageNet project, a visual database used for researching computer image recognition. The project’s database consists of over 14 million images designed for training convolutional neural networks in image classification and object detection tasks.
The official name of the ImageNet annual contest, which started in 2010, is the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The goal of the ILSVRC is for teams to compete with each other for the most accurate image recognition software.
Popular architectures for image classification
The ImageNet classification challenged has introduced many popular convolutional neural networks since it was established, which are now widely used in the industry. This is highly important in AI for image recognition, given that the ability to optimize a CNN architecture has a big effect on its performance and efficiency.
Here are a few examples of the architectures of the winning CNNs of the ILSVRC:
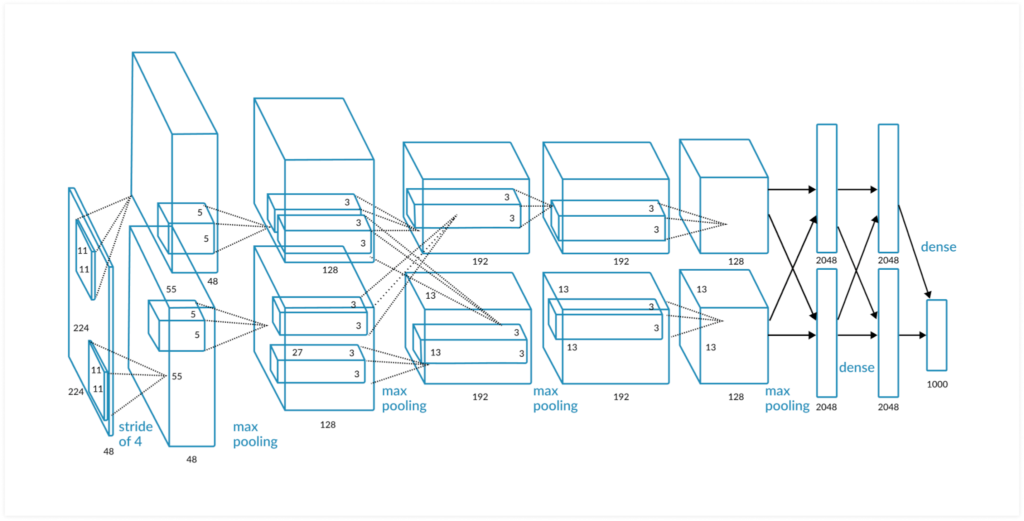
AlexNet (2012)
A CNN designed by SuperVision group, it gained popularity of it dropped the average classification rate in the ILSVRC by about 10%. It is comprised of five convolutional layers, followed by three fully connected layers. Compared to LeNet, it has more filters per layer and stacked convolutional layers.
One of the reasons AlexNet managed to significantly reduce the average classification rate is its use of faster ReLU for the non-linear part instead of traditional, slower solutions such as Tanh or Sigmond functions. Additionally, SuperVision group used two Nvidia GTX 580 Graphics Processing Units (GPUs), which helped them train it faster.
GoogleNet (2014)
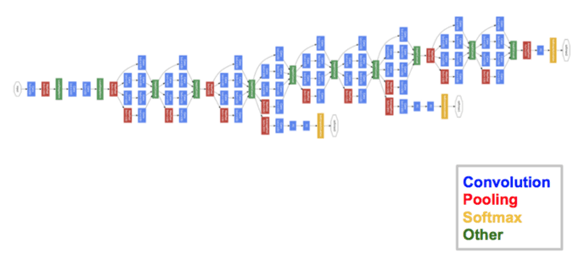
This network, made by a team at Google and also named Inception V1, achieved a top-5 error rate lower than 7%, was the first one that came close to the human-level performance.
The architecture of GoogleNet is 22 layers deep. The team implemented a module they designed called “inception module” to reduce the number of parameters by using batch normalization, RMSprop and image distortions. GoogleNet only has 4 million parameters, a major leap compared to the 60 million parameters of AlexNet.
ResNet (2015)
Residual Neural Network (ResNet) achieved a top-5 error rate of 3.57% and was the first to beat human-level performance on the ILSVRC dataset.
ResNet can have up to 152 layers. It uses “skip connections” (also known as gated units) to jump over certain layers in the process and introduces heavy batch normalization. The smart implementation of the architecture of ResNet allows it to have about 6 times more layers than GoogleNet with less complexity.
Example and Code : https://indiantechwarrior.com/all-about-tensorflow-resnet/




