
What are Artificial Neural Networks and Deep Neural Networks?
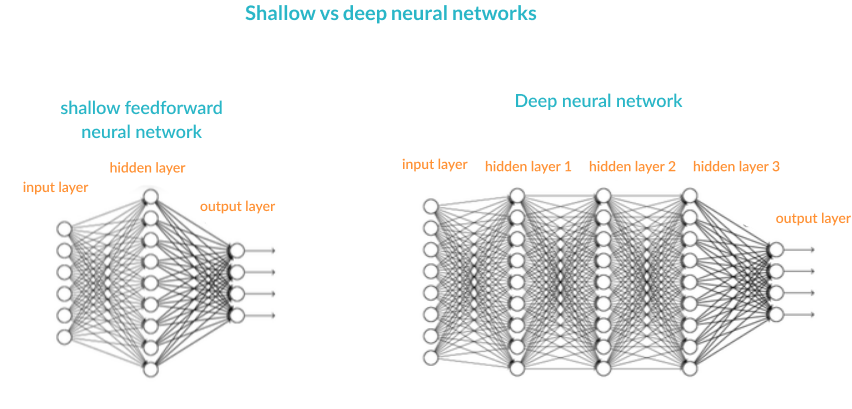
Artificial Neural Networks (ANN) is a supervised learning system built of a large number of simple elements, called neurons or perceptrons. Each neuron can make simple decisions, and feeds those decisions to other neurons, organized in interconnected layers. Together, the neural network can emulate almost any function, and answer practically any question, given enough training samples and computing power. A “shallow” neural network has only three layers of neurons:
- An input layer that accepts the independent variables or inputs of the model
- One hidden layer
- An output layer that generates predictions
A Deep Neural Network (DNN) has a similar structure, but it has two or more “hidden layers” of neurons that process inputs. Goodfellow, Bengio and Courville showed that while shallow neural networks are able to tackle complex problems, deep learning networks are more accurate, and improve in accuracy as more neuron layers are added. Additional layers are useful up to a limit of 9-10, after which their predictive power starts to decline. Today most neural network models and implementations use a deep network of between 3-10 neuron layers.
The Basics of Artificial Neural Networks
Inputs – Source data fed into the neural network, with the goal of making a decision or prediction about the data. Inputs to a neural network are typically a set of real values; each value is fed into one of the neurons in the input layer.
Training Set – A set of inputs for which the correct outputs are known, used to train the neural network.
Outputs – Neural networks generate their predictions in the form of a set of real values or boolean decisions. Each output value is generated by one of the neurons in the output layer.
Neuron/perceptron – The basic unit of the neural network. Accepts an input and generates a prediction. Each neuron accepts part of the input and passes it through the activation function. Common activation functions are sigmoid, TanH and ReLu. Activation functions help generate output values within an acceptable range, and their non-linear form is crucial for training the network.
Weight Space – Each neuron is given a numeric weight. The weights, together with the activation function, define each neuron’s output. Neural networks are trained by fine-tuning weights, to discover the optimal set of weights that generates the most accurate prediction.
Forward Pass – The forward pass takes the inputs, passes them through the network and allows each neuron to react to a fraction of the input. Neurons generate their outputs and pass them on to the next layer, until eventually the network generates an output.
Error Function – Defines how far the actual output of the current model is from the correct output. When training the model, the objective is to minimize the error function and bring output as close as possible to the correct value.
Backpropagation – In order to discover the optimal weights for the neurons, we perform a backward pass, moving back from the network’s prediction to the neurons that generated that prediction. This is called backpropagation. Backpropagation tracks the derivatives of the activation functions in each successive neuron, to find weights that brings the loss function to a minimum, which will generate the best prediction.
Bias and Variance – When training neural networks, like in other machine learning techniques, we try to balance between bias and variance. Bias measures how well the model fits the training set—able to correctly predict the known outputs of the training examples. Variance measures how well the model works with unknown inputs that were not available during training. Another meaning of bias is a bias neuron which is used in every layer of the neural network.
Hyperparameters – A hyperparameter is a setting that affects the structure or operation of the neural network. In real deep learning projects, tuning hyperparameters is the primary way to build a network that provides accurate predictions for a certain problem. Common hyperparameters include the number of hidden layers, the activation function, and how many times (epochs) training should be repeated.




