
There are many effective ways to automatically classify entities. In this article, we cover six common classification algorithms, of which neural networks are just one choice. Which algorithm is the best choice for your classification problem, and are neural networks worth the effort?
Artificial Neural Networks and Deep Neural Networks are effective for high dimensionality problems, but they are also theoretically complex. Fortunately, there are deep learning frameworks, like TensorFlow, that can help you set deep neural networks faster, with only a few lines of code.
What Is Classification in Machine and Deep Learning?
Classification involves predicting which class an item belongs to. Some classifiers are binary, resulting in a yes/no decision. Others are multi-class, able to categorize an item into one of several categories. Classification is a very common use case of machine learning—classification algorithms are used to solve problems like email spam filtering, document categorization, speech recognition, image recognition, and handwriting recognition.
In this context, a neural network is one of several machine learning algorithms that can help solve classification problems. Its unique strength is its ability to dynamically create complex prediction functions, and emulate human thinking, in a way that no other algorithm can. There are many classification problems for which neural networks have yielded the best results.
Types of Classification Algorithms: Which Is Right for Your Problem?
To understand classification with neural networks, it’s essential to learn how other classification algorithms work, and their unique strengths. For many problems, a neural network may be unsuitable or “overkill”. For others, it might be the only solution.
Logistic Regression

Classifier type
Binary
How It Works
Analyzes a set of data points with one or more independent variables (input variables, which may affect the outcome) and finds the best fitting model to describe the data points, using the logistic regression equation:

Strengths
Simple to implement and understand, very effective for problems in which the set of input variables is well known and closely correlated with the outcome.
Weaknesses
Less effective when some of the input variables are not known, or when there are complex relationships between the input variables.
Decision Tree Algorithm
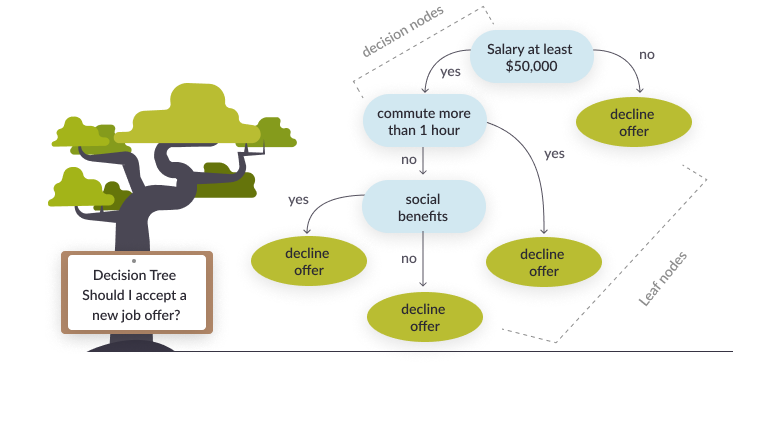
Classifier type
Multiclass
How it works
Uses a tree structure with a set of “if-then” rules to classify data points. The rules are learned sequentially from the training data. The tree is constructed top-down; attributes at the top of the tree have a larger impact on the classification decision. The training process continues until it meets a termination condition.
Strengths
Able to model complex decision processes, very intuitive interpretation of results.
Weaknesses
Can very easily overfit the data, by over-growing a tree with branches that reflect outliers in the data set. A way to deal with overfitting is pruning the model, either by preventing it from growing superfluous branches (pre-pruning), or removing them after the tree is grown (post-pruning).
Random Forest Algorithm
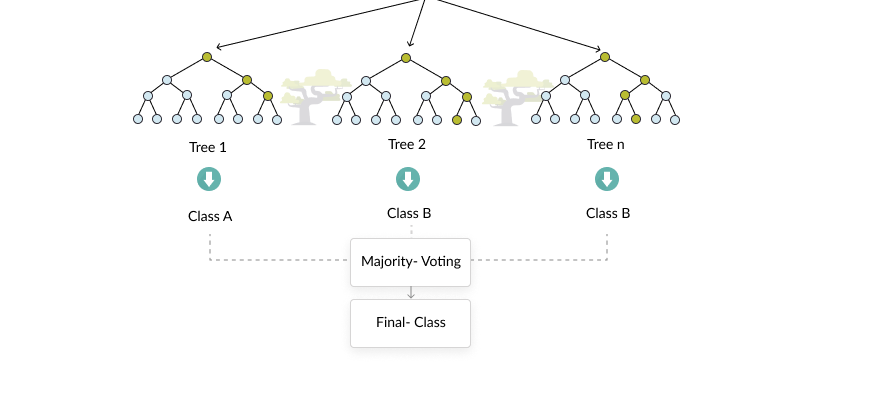
Classifier type
Multiclass
How it works
A more advanced version of the decision tree, which addresses overfitting by growing a large number of trees with random variations, then selecting and aggregating the best-performing decision trees. The “forest” is an ensemble of decision trees, typically done using a technique called “bagging”.
Strengths
Provides the strengths of the decision tree algorithm, and is very effective at preventing overfitting and thus much more accurate, even compared to a decision tree with extensive manual pruning.
Weaknesses
Not intuitive, difficult to understand why the model generates a specific outcome.
Naive Bayes Classifier

Classifier type
Multiclass
How it works
A probability-based classifier based on the Bayes algorithm. According to the concept of dependent probability, it calculates the probability that each of the features of a data point (the input variables) exists in each of the target classes. It then selects the category for which the probabilities are maximal. The model is based on an assumption (which is often not true) that the features are conditionally independent.
Strengths
Simple to implement and computationally light—the algorithm is linear and does not involve iterative calculations. Although its assumptions are not valid in most cases, Naive Bayes is surprisingly accurate for a large set of problems, scalable to very large data sets, and is used for many NLP models. Can also be used to construct multi-layer decision trees, with a Bayes classifier at every node.
Weaknesses
Very sensitive to the set of categories selected, which must be exhaustive. Problems where categories may be overlapping or there are unknown categories can dramatically reduce accuracy.
k-Nearest Neighbor (KNN)

Classifier type
Multiclass
How it works
Classifies each data point by analyzing its nearest neighbors from the training set. The current data point is assigned the class most commonly found among its neighbors. The algorithm is non-parametric (makes no assumptions on the underlying data) and uses lazy learning (does not pre-train, all training data is used during classification).
Strengths
Very simple to implement and understand, and highly effective for many classification problems, especially with low dimensionality (small number of features or input variables).
Weaknesses
KNN’s accuracy is not comparable to supervised learning methods. Not suitable for high dimensionality problems. Computationally intensive, especially with a large training set.
Artificial Neural Networks and Deep Neural Networks

Classifier type
Either binary or multiclass
How it works
Artificial neural networks are built of simple elements called neurons, which take in a real value, multiply it by a weight, and run it through a non-linear activation function. By constructing multiple layers of neurons, each of which receives part of the input variables, and then passes on its results to the next layers, the network can learn very complex functions. Theoretically, a neural network is capable of learning the shape of just any function, given enough computational power.
Strengths
Very effective for high dimensionality problems, able to deal with complex relations between variables, non-exhaustive category sets and complex functions relating input to output variables. Powerful tuning options to prevent over- and under-fitting.
Weaknesses
Theoretically complex, difficult to implement (although deep learning frameworks are readily available that do the work for you).Non-intuitive and requires expertise to tune. In some cases requires a large training set to be effective.




